Database vs Data Warehouse vs Data Lake
As an analyst, my job is to answer analytical questions that can’t be investigated by simply using a Business Intelligence (BI) tool. While modern BI tools offer the ability to query your data in different ways, you’re at the mercy of the pre-built transformations designed by the underlying Data Warehouse. In such instances, an analyst can bypass the data warehouse and retrieve data from the underlying source databases. While this seems normal to me now, I initially found it odd to have what appeared to me as unnecessary copies of data within a database, a data warehouse, and (more recent times) a data lake. The intent of this blog post is to shed some light on the differences among these three data architectures.
Database
A database is an organized collection of transaction-oriented data from day to day operational systems. Data stored in a database is highly structured, i.e. stored in a series of related tables to accurately & quickly capture a predefined set of transaction details. When you make an online order on ecommerce company XYZ’s website, your order is considered a transaction and triggers the company’s orders management system to update a database. Within the database, XYZ’s Orders Fact Table gets updated to include the order details such as the customer, timestamp, and product. To ensure data accuracy, underlying data attributes are stored in separate reference tables known as Dimension Tables. Rather than entering customer details such as name, address, phone number anytime time a transaction gets processed, such details are maintained in Dimension Tables and linked to the Orders Fact Table. In the Orders Fact Table, the transactions are listed using reference keys such as ‘CustomerID’. This helps avoid having customer ‘Benson Igarabuza and ‘benson Igarabuza’ recorded as different customers as the customer can be referenced to using ‘CustomerID’: 123. This approach is referred to as Normalization and is best summarized using visualizations of the tables and relationships called a Schema such as the below Microsoft Access snapshot:
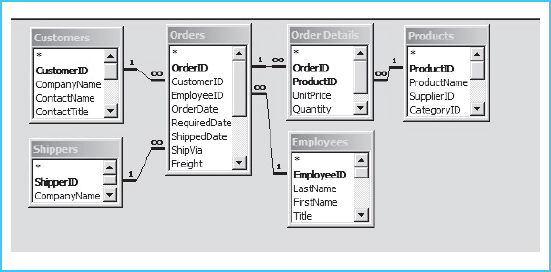
If you extrapolate the Normalization approach to various business processes such accounting, marketing, and inventory management, you would end up with an extensive and detailed web of tables and relationships. While it may appear complicated, normalization not only ensures data integrity but also saves on data storage. The use of reference keys also retrieve transactional data in an efficient manner, creating a timely experience for customers. This architecture lends well for day to day operations within the various departments in an organization. A problem arises, however, when trying to get a broad company-wide data set for analysis. Joining the various tables scattered across several departments requires significant resources and can be challenging, especially given the number and variety of analytical questions needing to be answered. This problem is tackled with a different data architecture – a Data Warehouse.
Data Warehouse
A data warehouse is a collection of structured data from various sources to be used for analytical purposes through a process called Transformation. Transforming database schemas includes a process of Denormalization. As this name implies, a Data Warehouse undoes the Normalization within a database by joining tables from various schemas to answer predefined analytical questions. In addition to denormalization, the transformation process cleanses the data by removing redundancies and standardizes the data sets.. If XYZ wanted to get a holistic view of their most loyal and paying customers, a Data Warehouse can answer this by combining customer details from the Marketing, Sales, and Accounting departments. The Marketing department database has metrics on how customers respond to various marketing campaigns. The Sales department database specifies which items were sold to which customers, while the accounting department database documents money collected on those sales. Denormalization joins only relevant tables from the three databases whereas reference keys such as CustomerIDs must be mapped (as each database likely has its own version of a CustomerID). An analyst can then easily run a performant query on the Data Warehouse as only relevant tables are included. The analyst is spared the burden of understanding the intricate details of how data is stored across the various departments. This architecture has worked for decades and modern Data Warehouses are designed to answer a very broad set of business questions. To explore data outside of the structured constraints of a Data Warehouse, however, an alternative solution is used - a Data Lake.
Data Lake
A data lake stores structured and unstructured data in its raw format rather than in tables. There’s been a growing movement to gain more business insights from unstructured data such as audio & video data, images, log files, and smart device data. Data saved in raw format lends well to exploratory data analysis as the data hasn’t been curated to answer a specific set of predefined questions. These data formats have historically received limited analysis, buttheoretically, a company may get an edge effectively analyzing it. A data scientist could develop a model to get a deep understanding of how the company’s most loyal and paying customers perceive the company by combining structured customer data from the various customer databases and unstructured audio files from customer call logs. The insights, it is thought, could be used to drive the company’s overall strategy on how it engages with its customers.
Conclusion
So there you have it; a database stores all your transaction-oriented data and serves daily operational needs, a data warehouse combines data from all your organization’s disparate sources,and a data lake goes even further byingesting all the data that comes in unstructured formats. These data architectures, particularly the database and data warehouse, are critical as an organization grows and accumulates more data.